|
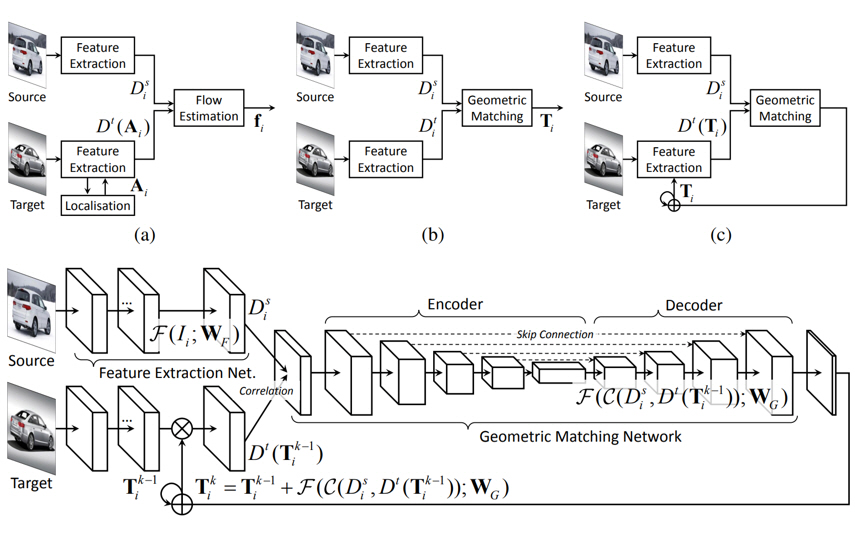
Intuition of RTNs: (a) methods for geometric invariance in the feature extraction step, e.g., STN-based methods [5, 19], (b) methods for geometric invariance in the regularization step, e.g., geometric matching-based methods [30, 31], and (c) RTNs, which weave the advantages of both existing STN-based methods and geometric matching techniques, by recursively estimating geometric transformation residuals using geometry-aligned feature activations.
|
